
97 Things Every SRE Should Know-07
Table of Contents
Thinking About Resilience
关于弹性的思考
在弹性系统中,即使其他变量离开正常状态,重要的变量也会保持在理想状态。例如,许多动物能够避免因轻微割伤而死亡。当皮肤被割破时,未受保护的载血组织会暴露出来,然而随着血块的形成,失血量很快就会趋于零。提高一个系统的弹性,使得描述该系统的因变量更加独立。
网络系统往往需要快速响应,表现为这样的状态:99百分位数的延迟低于一秒。理想情况下,这个状态一直保持到系统所需的极限,例如,1s的峰值请求率为100000/秒。我们要保证延迟变量不至于太依赖请求率变量。
以下是我们提高弹性的方法。 减少负载(Load reduction) 节流、负载分流/优先级、排队、负载平衡。 减少延迟(Latency reduction) 缓存、区域复制 负载适应性(Load adaptation) 自动扩展、过度供应 弹性(具体而言)Resilience (specifically) 超时、断路器、隔板、重试、故障切换、后备箱。 元技术Meta-techniques 改进工具,也许是为了更快地扩大规模或失效;特别是当慢速的人类在系统的关键路径上时,影响更大。
其中一些工具通常与弹性无关(它们是一般的优化技术),但都会影响关键变量的依赖性。有时,它们以有用的方式相互作用。例如,重试可以纠正故障切换造成的短暂停机。
这些工具也会在多层重复出现。TCP重传对数据包丢失起作用,但也使用应用层重试,因为TCP不能重试整个流(还有其他原因)。
我们继续说延迟的例子。在实践中,请求率和延迟之间的关系并不是线性的,通常遵循一些合理的功能。在达到一定负载之前,系统是不饱和的,可以快速响应,但当负载接近容量时,队列很快就会被填满,延迟也会相应增长。
我们可以通过添加服务器来扩展系统,这将横向扩展功能,允许在违背延迟目标之前为更多请求提供服务。这是要花钱的。如果我们不喜欢这样,我们可以考虑其他选项,比如负载减少:当系统过载(延迟达到极限)时,丢弃请求(限制请求速率)。
错误也会带来金钱(收入)上的影响,但如果这种情况非常罕见的话,它可能比购买更多服务器的影响要小。先放弃不重要的工作,可以进一步降低成本。最重要的是,负载削减方法完全防止了无限制的延迟增长,避免了潜在的级联故障。
你可以按照下面的图示来思考每个弹性工具:
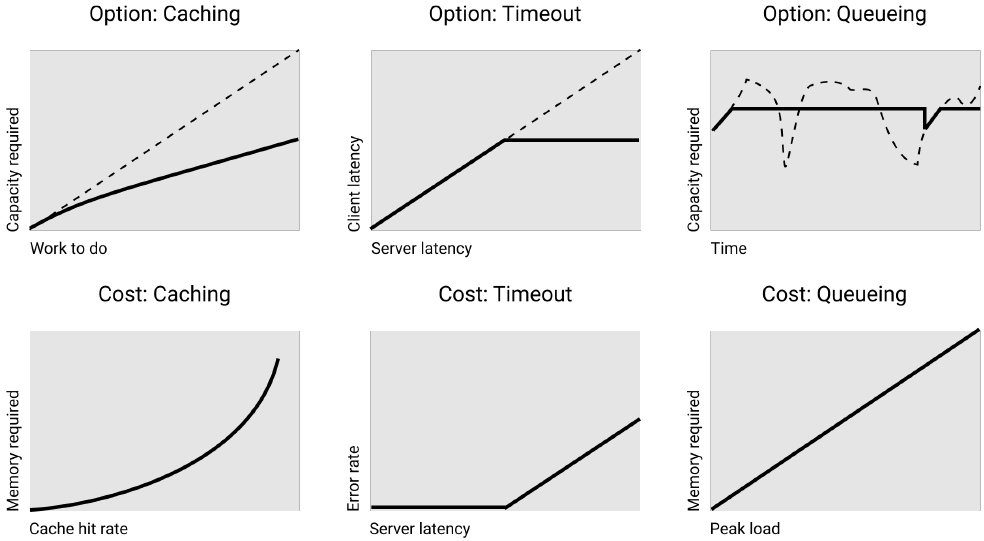 resilience-07
resilience-07
通过建立弹性,我们可以帮助提高可靠性,使系统在不利条件下恢复并继续运行。
我们如何构建本书的结构
SRE虽然涉及复杂的技术系统,但归根结底是一种文化实践。文化是人的产物,这启发我们根据你在组织中的SRE数量来组织本书的各个部分–你具体处理什么,你的一天是怎样的,取决于有多少个SRE工程师。我们将本书的文章分为 “SRE新手” 、0-1个SRE、1-10个SRE、10-100个SRE和 “SRE的未来 ”。
读者如果想找寻先从哪里开始的指导,可以直接跳到最适用于自己的部分;但是,你仍然会发现阅读那些目前并不适用于你日常的部分的文章的价值。
在0到1个SRE时,还没有人被指定为SRE,或者你已经找到了你的第一个SRE,这个角色看起来几乎是孤独的。
在1到10名SRE时,你正在组建一个团队,有知识共享和分工的能力。
在10到100个SRE时,你已经成为一个组织,你需要思考的不仅仅是你所从事的系统,还需要思考如何组织这么多SRE。
“SRE新手” 涵盖了基础性的话题(尽管并不详尽!),对于那些刚刚开始SRE之旅的人来说是很有帮助的,即使是最有经验的SRE,也是一种复习。 “SRE的未来” 包含了一些文章,这些文章探讨了SRE潜在的发展方向,或者是(目前)坐拥时代潮流。
没有必要按照任何特定的顺序阅读本书。你可以从头到尾读一遍。或者,如果你对某个特定的主题感到好奇,可以翻到索引,在那里你可以找到关于该主题的所有文章。把它作为参考指南,或者是灵感的来源–可以在需要的时候提供一个震撼。或者,也许可以建立一个阅读俱乐部,每周一次挑选一篇文章与同事讨论。这就是散文集的魅力所在。我们希望你和我们一样喜欢阅读它们。
结语
SRE系列的文章,有时间我就会翻译一些,希望大家能学到对自己有用的东西。谢谢